Database Connection Pool and Persistent Connection
Database Connection Pool and Persistent Connection
지속적인 연결(Persistent Connection) 이란?
영속적인 커넥션은 얼마간 연결을 열어놓고 여러 요청에 재사용함으로써, 새로운 TCP 핸드셰이크를 하는 비용을 아끼고, TCP의 성능 향상 기능을 활용할 수 있습니다. 커넥션은 영원히 열려있는지 않으며, 유휴 커넥션들은 얼마 후에 닫힙니다(서버는 Keep-Alive 헤더를 사용해서 연결이 최소한 얼마나 열려있어야 할지를 설정할 수 있습니다). from MDN web docs

출처: https://developer.mozilla.org/ko/docs/Web/HTTP/Connection_management_in_HTTP_1.x
위 그림을 보면 Multiple connections 또는 Short-lived connections (좌측)의 경우 3개의 요청을 처리하기 위해 커넥션을 매번 열었다 닫고있는 반면, Persistent connection (중앙)의 경우 하나의 커넥션으로 3개의 요청을 처리하는 것을 볼 수 있습니다.
Advantages (from wiki)
- 후속 요청에서 대기 시간 감소 (핸드 쉐이크 없음).
- 새로운 연결 및 TLS 핸드 셰이크가 적기 때문에 CPU 사용량 및 round-trips 시간이 줄어 듭니다.
- 요청 및 응답의 HTTP 파이프 라이닝을 활성화합니다 (위 그림 중 우측).
- 네트워크 혼잡 감소 (TCP 연결 감소).
- TCP 연결을 닫지 않아도 페널티없이 오류를보고 할 수 있습니다 (?).
Disadvantages (from wiki)
필요한 모든 데이터를 수신 한 후 클라이언트가 연결을 닫지 않으면 서버에서 연결을 유지하는 데 필요한 자원을 다른 클라이언트가 사용할 수 없게됩니다. 이것이 서버의 가용성에 영향을 미치는 정도와 리소스를 사용할 수없는 기간은 서버의 아키텍처 및 구성(max age, max connection 등)에 따라 다릅니다.
즉, 유휴 상태일때에도 서버 리소스를 소비하며, 과부하 상태에서는 DoS attacks을 당할 수 있습니다.
커넥션 풀(conneciton pool) 이란?
연결 풀 또는 커넥션 풀(connection pool)은 소프트웨어 공학에서 데이터베이스로의 추가 요청이 필요할 때 연결을 재사용할 수 있도록 관리되는 데이터베이스 연결의 캐시이다. 연결 풀을 사용하면 데이터베이스의 명령 실행의 성능을 강화할 수 있다. 각 사용자마다 데이터베이스 연결을 열고 유지보수하는 것은 비용이 많이 들고 자원을 낭비한다. 연결 풀의 경우 연결이 수립된 이후에 풀에 위치해 있으므로 다시 사용하면 새로운 연결을 수립할 필요가 없어진다. 모든 연결이 사용 중이면 새로운 연결을 만들고 풀에 추가된다. 연결 풀은 사용자가 데이터베이스에 연결을 수립하는데까지 대기해야하는 시간을 줄이기도 한다. from wikipedia
즉, DB 연결(connection)을 매번 여는 비용을 줄이기 위해 미리 만들어 놓고 재사용하는 것입니다.
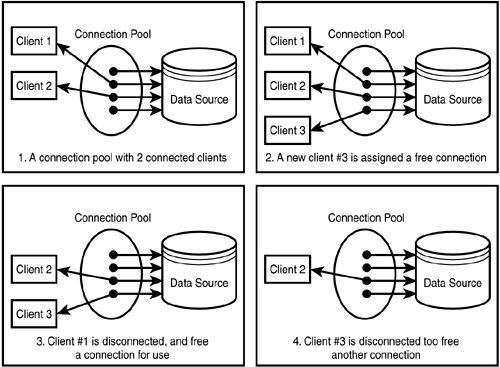
위 그림을 보면, 커넥션 풀에 4개의 커넥션을 미리 만들어 두고, 클라이언트의 요청이 들어올 경우 새로 생성하는 것이 아니라 미리 생성된 커넥션으로 처리하는 것을 볼 수 있습니다. 만약 커넥션 풀 내의 모든 커넥션이 사용중이라면 클라이언트는 대기 상태로 전환되고, 커넥션이 반환되면 대기하고 있는 순서대로 커넥션이 제공됩니다. 만약 커넥션 풀을 사용하지 않는 경우 최대 커넥션 개수를 초과하면 에러로 인해 서버가 다운될 수 있습니다.
Connection Pooling vs. Persistent Connections
위 설명만 봐서는 두 가지가 유사해 보입니다. 지속적 연결의 경우 생명이 정해져 있지만 커넥션 풀링에서는 정해져 있지 않다? 지속적 연결은 최대 개수를 설정하지 않지만 커넥션 풀링에서는 정해져 있다? 여러 서비스들을 살펴보면 지속적 연결과 커넥션 풀링이 비슷한 설정들을 사용하고 있습니다. 지속적 연결에서도 최대 개수를 지정해서 시스템에서 지원하는 최대 개수를 넘지 않도록 할 수 있고, 커넥션 풀링에서도 지속 시간을 두어 일정 시간마다 다시 열도록 설정할 수도 있습니다. 그렇다면 가장 큰 차이점은 무엇일까요?
지속적인 연결(Persistent Connections)은 psycopg2, PDO, Hibernate 및 SQLObject와 같은 드라이버, 드라이버 프레임워크 및 ORM 도구의 기능입니다. 드라이버는 커넥션 핸들을 열어두어 동일한 프로세스 또는 쓰레드에서 데이터베이스 엑세스가 다시 발생하는 경우 그것을 재사용합니다. 이를 통해 데이터베이스 인증 및 연결 시작 시간으로 인한 대기 시간을 줄일 수 있습니다. 연결 풀링(Connection Pooling)은 pgBouncer 및 다양한 J2EE 서버와 같은 네트워크 프록시 및 응용 프로그램 서버의 기능입니다. 데이터베이스에 대한 지속적인 연결 풀이 유지되고 여러 응용 프로그램 서버간에 공유되어 하나 이상의 응용 프로그램 프로세스가 동일한 데이터베이스 커넥션을 공유 할 수 있는 경우가 많습니다. 이렇게하면 연결 시작 시간이 줄어들뿐만 아니라 적은 수의 데이터베이스 서버 커넥션을 보다 잘 관리할 수 있으므로 데이터베이스 서버의 로드가 줄어듭니다. 사용중인 툴에 최대 데이터베이스 연결 수 및 데이터베이스 연결 수명에 대한 구성 매개 변수가 없거나 별도의 서비스가 실행되지 않는 경우 연결 풀이 아닐 수 있습니다. 출처: http://www.databasesoup.com/2013/07/connection-pooling-vs-persistent.html
위 내용에서 보면, 지속적 연결은 단일 프로세스 내에서 동일한 프로세스 또는 쓰레드가 데이터베이스에 연결하는 것에 대한 기능입니다. 반면, 연결 풀링의 경우 다중 프로세스에서 데이터베이스에 연결하는 것데 대한 기능입니다. 연결 풀링 구현 중 하나인 pgBouncer는 연결 풀을 관리하는 프로세스가 독립적으로 동작하며, 응용 프로그램에서는 데이터베이스 대신 pgBouncer 프로세스에 접속하여 디비를 사용하게 됩니다.
Database Connection in Django
Django 1.5 버전까지는 모든 HTTP 리퀘스트에 대해 새로운 커넥션을 생성하여 처리하였으며, 1.6 버전부터 Persistent Connection을 적용하였습니다 (Django 1.6 release notes).
관련 설정으로 CONN_MAX_AGE 값을 통해 커넥션의 유지 시간을 조절할 수 있습니다:
- 0: 리퀘스트가 완료되면 연결을 닫음 (Default)
- Positive: 해당 시간동안 커넥션을 유지 (in seconds)
- None: 커넥션을 계속 열어둠
현재 Django는 커넥션 풀이 아닌 지속적인 연결을 사용하고 있습니다.
Generally speaking it’s because third party applications such as pgbouncer do it better.
관련 링크:
적절한 커넥션 개수는?
maxActive 값은 DBMS의 설정과 애플리케이션 서버의 개수, Apache, Tomcat에서 동시에 처리할 수 있는 사용자 수 등을 고려해서 설정해야 한다. DBMS가 수용할 수 있는 커넥션 개수를 확인한 후에 애플리케이션 서버 인스턴스 1개가 사용하기에 적절한 개수를 설정한다. 사용자가 몰려서 커넥션을 많이 사용할 때는 maxActive 값이 충분히 크지 않다면 병목 지점이 될 수 있다. 반대로 사용자가 적어서 사용 중인 커넥션이 많지 않은 시스템에서는 maxActive 값을 지나치게 작게 설정하지 않는 한 성능에 큰 영향이 없다.
